8. Trees & Graphs
Trees
Binary Tree
A binary tree is simply a hierarchical tree that has at most 2 children for any node
A Graph would mean any number of connections for a node, and there are similarities there, but binary (2) means at most 2 children and 1 parent
class TreeNode:
def __init__(self, val, left, right):
self.val = val
self.left = left
self.right = right
Binary Tree's are both specific types of Graphs, and so are Linked Lists actually
Binary Search Tree
Binary Search Tree's are tree's who, for any node, have:
- All left children node value
- All right children node value
The reason these are different from regular Binary Tree's are this specific relationship - at each step you can reduce the total search space by half, resulting in search time
You can reduce it because there's a specific relationship ,
Self-Balancing Binary Search Tree
- Self Balancing BST's have the same property as Binary Search Tree's, except they will balance themselves out via different methods
- The reason for this balancing is that Binary Search Tree's worst case lookup time degrades to if the tree represents a Linked List
- This usually happens when you insert nodes in order and it becomes all right or left sides
AVL Tree
Red Black Tree
Segment Tree
A segment tree is a Binary Tree where each node represents an interval, and each node would store one or more properties of an interval that'd be queried later on
Most of the time it's segements / indexes of an array, and the total sum, count, or some aggregation over them, which allows us to find a certain aggregation over a range of data in potentially time
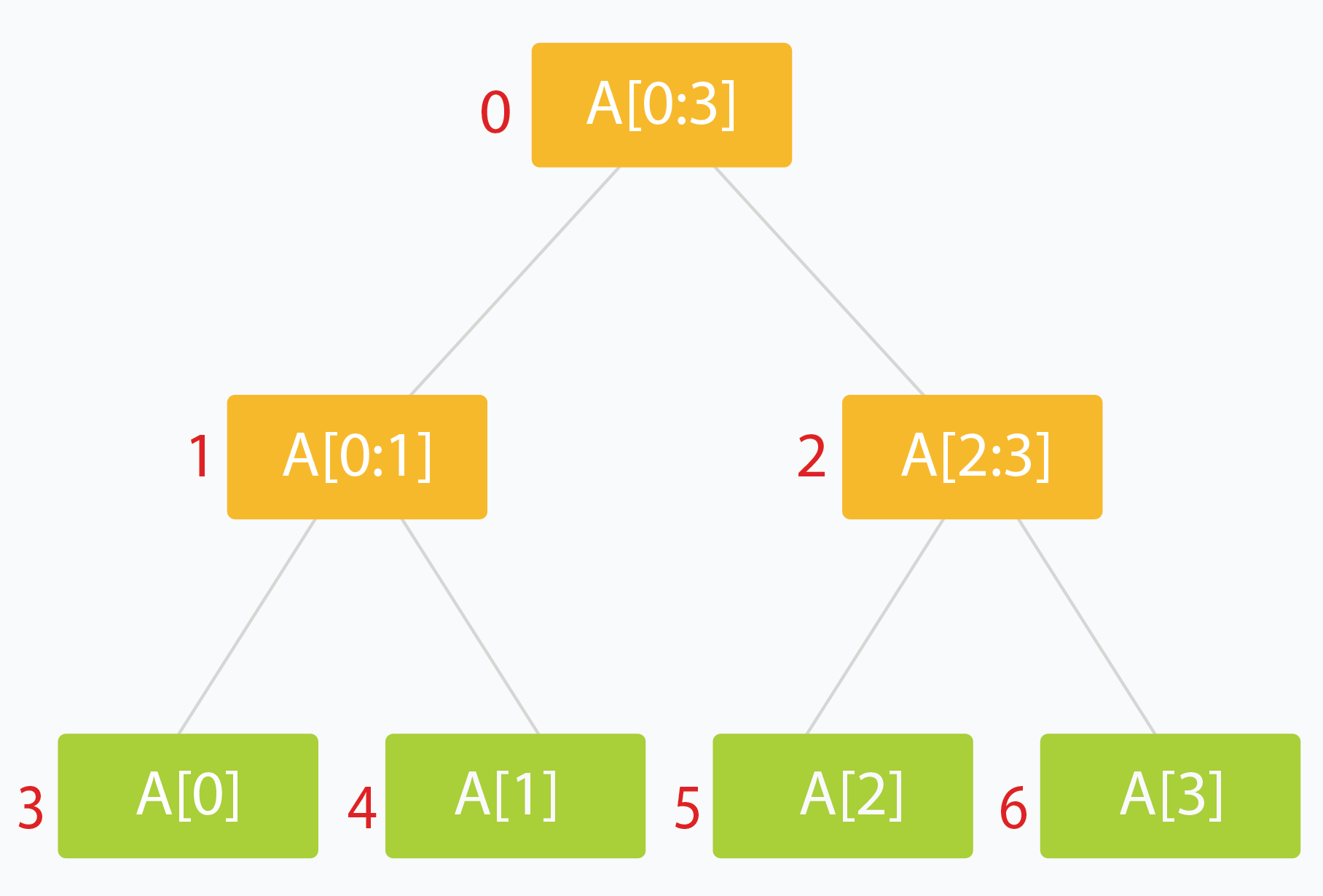
- Typically the root holds the entire interval of data we're interested in traversing
- Each leaf of the tree represents a range of just one single element
- The internal nodes would represent the merged or unioned result of their children nodes
- Ideally, each child node would represent about 1/2 of it's parent
- Implementation:
- Single callable function
- Recurses down until at leaf node, and stores singular value in leaf node
- After exiting later on in recursive call merge the child values via array lookup
void buildSegTree(vector<int>& arr, int treeIndex, int lo, int hi)
{
if (lo == hi) { // leaf node. store value in node.
tree[treeIndex] = arr[lo];
return;
}
int mid = lo + (hi - lo) / 2; // recurse deeper for children.
buildSegTree(arr, 2 * treeIndex + 1, lo, mid);
buildSegTree(arr, 2 * treeIndex + 2, mid + 1, hi);
// merge build results
tree[treeIndex] = merge(tree[2 * treeIndex + 1], tree[2 * treeIndex + 2]);
}
// call this method as buildSegTree(arr, 0, 0, n-1);
// Here arr[] is input array and n is its size.
- The more important part is querying
- you can't read partial overlaps, it would be too confusing
- Need to traverse down until you get to a section that's smaller than your desired interval, and worst case add in from other sections as well
- Can hopefully use some internal / middle nodes, and complete the aggregation using other leaf nodes
- Updating values means finding the leaf node of the actual index, and traversing back up and out to update that leaves parents
Prefix Sum
- The Prefix Sum is defined, for 1-D arrays, in Arrays and Strings
- The Prefix Sum also comes up in Tree Traversal because you can use it during a tree traversal technique to find things like
- Total number of paths that sum to X
- Total number of paths less than or equal to X
- etc
- The same "problems" that Prefix Sum solves for Arrays it can solve for in Trees as well
There is just one thing that is particular for the binary tree...there are two ways to go forward - to the left and to the right
To keep parent->child direction, you shouldn't blend prefix sums from the left and right subtrees in one hashmap
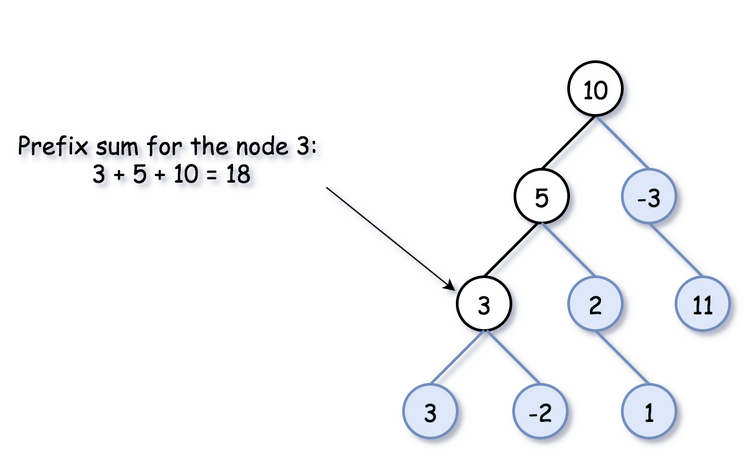
So to do this for Binary Tree you start off by defining some global variables
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
resp = 0
target = targetSum
freq = defaultdict(int)
preorder(root, 0)
return(resp)
And then you need to create the traversal code
Weird part is removing it from freq after passing, but just means you take it out so other traversals aren't affected by it, and is from Backtracking - it ensures that when you return from a recursive call (i.e., move back up the tree), the prefix sum count for the current path is removed from the frequency map
target = 3
1
/ \
2 3
root(1) - currSum = 1, freq = {0:1, 1:1}
left to 2 - currSum = 1 + 2 = 3, freq = {0:1, 1:1, 3:1}
Done
Move back up
freq[3] -= 1 --> freq = {0:1, 1:1, 3:0}
Right to 3 - currSum = 1 + 3 = 4, freq = {0:1, 1:1, 3:0, 4:1}
Although this wouldn't affect this specific problem, with a large enough tree there'd be sums thrown all throughout here that would most likely affect the outcome
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
def preorder(curr: Optional[TreeNode], currSum: int) -> None:
nonlocal resp # use the global variable
# check existence here, not if left then left, if right then right
if not curr:
return
currSum += curr.val
if currSum == target:
resp += 1
resp += freq[currSum - target]
freq[currSum] += 1
preorder(curr.left, currSum)
preorder(curr.right, currSum)
# Remove this from map so you don't use it in other parts of tree
freq[currSum] -= 1
resp = 0
target = targetSum
freq = defaultdict(int)
preorder(root, 0)
return(resp)
Traversal Types
Depth First Search
Depth first search (DFS) prioritizes searching as far as possible along a single route in one direction until reaching a leaf node before considering another direction
DFS is typically only used in tree traversals, as graphs have circles and odd structures - tree's you can "go to the end" meaning a leaf node in a reasonable fashion
DFS utilizes a similar template structure to binary tree's above, but in DFS you choose what operations you do with the nodes themselves
def dfs(node):
if node == None:
return
dfs(node.left)
dfs(node.right)
return
There are 3 main types of DFS, and all of them relate to where you engage with the root node:
- Inorder traversal is left, root, right
- Preorder traversal is root, left, right
- Postorder traversal is left, right, root
def dfs(node):
if node == None:
return
# operation(root) - preorder
dfs(node.left)
# opertaion(root) - inorder
dfs(node.right)
# operation(root) - postorder
return
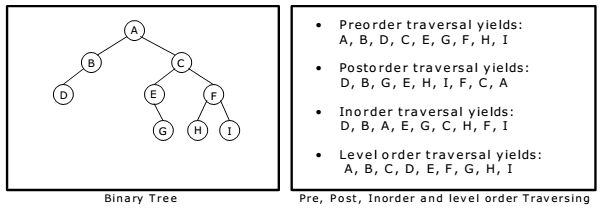
Recursion Stack
Each function call to dfs() solves and returns the answer ot the original problem (in the call stack) as if the subtree rooted at the current node was the input
Most use cases of DFS utilize recursion, and underneath the hood recursion is simply a stack
In the below tree, if we ran an inorder traversal the output would be 3, 1, 0, 4, 2, 5
0
/ \
1 2
/ / \
3 4 5
def dfs(node):
if node == None:
return
dfs(node.left)
print(root) - inorder
dfs(node.right)
return
Looking at the call stack we would see:
call_stack = []dfs(root) --> call_stack = [dfs(0)]- Inside of
dfs(0)- Call
dfs(0.left) --> call_stack = [dfs(0), dfs(1)]- Inside of
dfs(1)- Call
dfs(1.left) --> call_stack = [dfs(0), dfs(1), dfs(3)]- Inside of
dfs(3)- Call
dfs(3.left) --> call_stack = [dfs(0), dfs(1), dfs(3), dfs(None)]- Inside of
dfs(None) --> return None call_stack = [dfs(0), dfs(1), dfs(3)]
- Inside of
- Call
print(root) --> 3 - Call
dfs(3.right) --> call_stack = [dfs(0), dfs(1), dfs(3), dfs(None)]- Inside of
dfs(None) --> return None call_stack = [dfs(0), dfs(1), dfs(3)]
- Inside of
- Exit
dfs(3)
- Call
- Inside of
- Call
print(root) --> 1(at this point output is 3, 1) - Call
dfs(1.right) --> call_stack = [dfs(0), dfs(1), dfs(None)]- Inside of
dfs(None) --> return None call_stack = [dfs(0), dfs(1)]
- Inside of
- Call
- Inside of
- Call
- Inside of
- And so on, and so forth!
The call_stack is just a stack that's pushe and popped to by the actual underlying python recursion, and this feature is available in basically every language. For DFS you can also implement this yourself, and it becomes an Iterable DFS solution where no recursion is involved - you simply do all of the stack calls yourself
Preorder is the cleanest implementation of this, and inorder and postorder are a bit tricky
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
if not root:
return 0
stack = [(root, 1)]
ans = 1
while stack:
curr_node, curr_depth = stack.pop()
# preorder operation(root)
ans = max(ans, curr_depth)
# dfs(left)
if curr_node.left:
stack.append((curr_node.left, curr_depth + 1))
# dfs(right)
if curr_node.right:
stack.append((curr_node.right, curr_depth + 1))
In this way, you never leave the initial maxDepth call, and you just implement everything on a stack yourself
Time complexity - there are nodes, so we are guaranteed to do work
- Typically
operation(root)is an operation, but it may also be some other - If it's then the entire thing is , if it's then
- Altogether, the time complexity is , where is typical
Space complexity is
- Usually in the worst case, as you're placing all of these calls onto a stack and if the tree is straight up and down (linked list) you can reach
- If the tree is perfectly balanced, space complexity becomes
Breadth First Search
Breadth First Search (BFS) is another way to traverse tree's and graphs, but is different from DFS in that it checks row by row instead of traversing down left, right, etc depth wise
The real difference between the 2 lies in their efficiencies on problems:
- BFS is better if the node is higher up, or if the logic requires level based logic
- DFS is better if the node is easily found traversing depth wise, or if the logic requires it!
- DFS space complexity, in typical cases, revolves around height of the tree and ends up being , but BFS is based on the largest span of the tree, and in a perfectly balanced tree would result in as the bottom row would have nodes in it
- Time complexity they're usually equivalent, unless the tree structure and problem statement are weird enough to cause them to deviate
- Using underlying deque data structure is required, as using a list wil cause time complexity to explode with inserts
from collections import deque
def print_all_nodes(root):
queue = deque([root])
while queue:
nodes_in_current_level = len(queue)
# do some logic here for the current level
for _ in range(nodes_in_current_level):
node = queue.popleft()
# do some logic here on the current node
print(node.val)
# put the next level onto the queue
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
Binary Search Tree
In a binary search tree, there's some special properties where, for any Vertex V, it's right child is greater than it's value, and its left child is less than it's value
Ultimately it's just a way to restructure a Linked List so that search is in time - this entire concept is the idea of Self-Balancing Binary Search Trees such as B-Tree's. Self balancing tree's have less efficient writes (since they need to find where to place nodes and do some restructuring), but the idea is that reads are much more efficient
A Binary Search Tree has similar code structure to Lists
def search_bst(root, target):
while root is not None:
if root.val == target:
return True
elif target < root.val:
root = root.left
else:
root = root.right
return False
BST's follow similar time and space complexity to Binary Search, but when you traverse a BST itself you use recursion / DFS for the actual recursion, and you'd simply choose left or right instead of going down both paths
Graphs
At it's core a Graph is a data structure consisting of two components - vertices (or nodes) and edges (connections between nodes)
Then a Graph is defined by these sets of vertices and edges, both and are sets of objects
Let's say there are vertices, with edges overall, where each node can have up to features
In most production implementations the set will consist of triplets, which are objects of where represents the weight of the edge between vertices and . Other times it will include other information, so that represents a set of relationships, but ultimately the relationships are defined by concepts such as "friends with", or "employs" or some other relationship that may or may not have weight. These features can be represented in a node feature matrix
A Graph is often stored and represented digitally using an adjacency list or adjacency matrix - then where each node is both a row and a column, and represents the edge between vertices and
Most data structures can actually be considered specific dimensional graphs, lists are 1-dimensional graphs, trees are hierarchical graphs, images are consistently dimensioned graphs (pixel sizes), etc
Structuring
There are 2 main ways to structure a graph in memory, either via an Adjacency List or an Adjacency Matrix
- An Adjacency List is simply a list of lists, where each index represents a vertex, and the list at that index represents all of the connected vertices
- This is typically more space efficient for sparse graphs, where not every vertex is connected to every other vertex
- An Adjacency Matrix is a 2-D matrix where each row and column represents a vertex, and the value at that index represents the weight of the edge between those vertices (or 1 if unweighted, or 0 if no edge)
- This is typically more space efficient for dense graphs, where many vertices are connected to many other vertices
In most real world scenarios graphs are sparse, and so Adjacency Lists are more commonly used, and even those structures are further optimized and compressed to ensure space efficiency
Representing a graph digitally is a large topic, and there are many more advanced structures like Compressed Sparse Row (CSR) or Compressed Sparse Column (CSC) formats that are used in large scale graph processing systems
For common API's on graphs we usually store 2 data structures:
- Node list / set
- Edge list / set
These 2 data structures allow us to traverse and manipulate the graph effectively, and are the basis for most graph algorithms - they also allow us to have heterogeneous graphs where different nodes and edges can have different types and properties. At the end of the day each of these properties typically extend an Object, so you can store any kind of data you want in them - the traversal algorithm is then expected to handle the different data types accordingly
Graph Traversal
Traversing a graph, similar to a tree, has generally 2 strategies, either Depth first or Breadth first. Separately from tree's, most graph recursive implementations need to hold onto some sort of seen = set() tracking system, similar to White / Black / Grey coloring in DFS recursion so that there isn't an infinite loop. Outside of that, the other major difference is that you don't pass node: TreeNode between dfs() calls, you have to pass node: int and use a separate data structure for storing edges, and then you traverse over those edges instead of .left or .right
- Depth first means exactly as it says, from any single node you traverse as far down / as far away as you can possibly go
- Breadth first on the other hand means from any node you explore each degree, or "level away", equally
- BFS is typically used in shortest path problems because as you go out a degree each level, you're guaranteed to hit the shortest path first, wheras DFS would need to search every path and then take
min()- Although for BFS to find the optimal solution, each edge has to have equal and positve weights, and so it wouldn't work for weighted edges - that's typiaclly when you would use Djikstra's algorithm
- BFS is typically used in shortest path problems because as you go out a degree each level, you're guaranteed to hit the shortest path first, wheras DFS would need to search every path and then take
is the number of Vertices, and is the number of edges
| Operation | Time Complexity | Space Complexity |
|---|---|---|
| Traverse | or if using hash map adjacency list | |
| Traverse Fully Connected Graph | and | or if using hash map adjacency list |
Graph Depth First Search
DFS involves the same data structures as mentioned above, and ultimately is the easier of the 2 to implement over graphs. The connected components example shows this, because any DFS from any node will eventually visit every node in that component, so ultimately you just use seen to track which node's you've visited so that you don't have to revisit them (infinite loop).
def dfs(start):
stack = [start]
while stack:
node = stack.pop()
for neighbor in graph[node]:
if neighbor not in seen:
seen.add(neighbor)
stack.append(neighbor)
Graph Breadth First Search
Similar to tree's, both DFS and BFS can work, but usually DFS is chosen as it's easier to implement compared to BFS
Instead of levels on a tree, BFS on graphs runs at levels from a source node - at any level d, we will directly store all nodes at level d+1 next for iterating over. So BFS, in either trees or graphs, is a useful tool that's required when you need to search things based on levels deep from, or levels away from, a node. In graphs, this mostly occurs in shortest path problems, because any level would describe the shortest number of hops it has taken to reach from source node - every time you reach a node that's not in seen, you must have reached it in the minimum steps possible from wherever you started your BFS
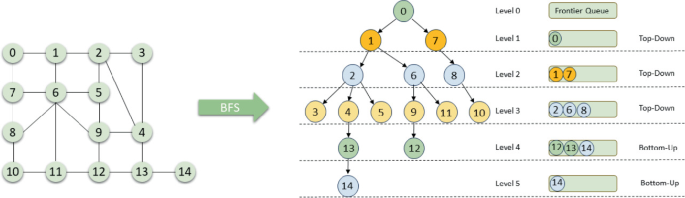
Outside of this, BFS uses the same deque data structure, and overall has a similar pattern to what it did in tree's, except you still need to check seen each time, and for the most part there is usually a maze or matrix with directions and adjacent cells we need to visit
while queue:
row, col, steps = queue.popleft()
if (row, col) == (n - 1, n - 1):
return steps
for dx, dy in directions:
next_row, next_col = row + dy, col + dx
if valid(next_row, next_col) and (next_row, next_col) not in seen:
seen.add((next_row, next_col))
queue.append((next_row, next_col, steps + 1))
Implicit Graphs
Similar to binary search solution space, there may be some implicit data structures that can be represented as graphs that we should check for - most occur as patterns of permutations, combinations, and choices from one inherent state to another
The time and space complexity of these problems revolves around the total number of states (nodes), and then the number of edges is usually also equal to that as you typically transition from one state to the other by tweaking one portion of the combination
Graph Problems and Advanced Data Structures
Some typical graph problems and extended data structures for solving them
Maze
Maze's are a special kind of graph where you essentially have a connected 2-D diagram
Most common examples are Finding The Nearest Exit or something similar, where you will use Breadth First Search to traverse outwards checking over the course of a structure
Connected Components
- Connected Components is a way for us to find all of the clusters in a graph, where connectivity can be weak, strong, or a few other types like unilaterally
- Weak connected components can be thought of as undirected connected components, so that edges are just generic edges
- Strongly connected components would require directed edges between all pairs of vertices meaning there has to be a way to get to any node, NodeA, from any other node in the component NodeB
- Algorithms:
- Breadth First Search:
- For all nodes, start a BFS traversal as long as they aren't marked as already visited
- Traverse all neighbors of , marking them as visited
- Continue the traversal until all nodes in the connected component of are visited
- Repeat for all unvisited nodes to find all connected components.
- UnionFind above will have the
rootvector at the end corresponding to all of the unique connected component ID's
- Breadth First Search:
Disjoint Set
Given the vertices and edges of a graph, how can we quickly check whether two vertices are connected? Is there a data structure that can help us identify if 2 nodes are apart of the same connected component? Yes! By utilizing the disjoint set (AKA union-find) data structure
The primary purpose of this data structure is to answer queries on the connectivity of 2 nodes in a graph in time
The optimized version is shown below
# UnionFind class
class UnionFind:
def __init__(self, size):
self.root = [i for i in range(size)]
# Use a rank array to record the height of each vertex, i.e., the "rank" of each vertex.
# The initial "rank" of each vertex is 1, because each of them is
# a standalone vertex with no connection to other vertices.
self.rank = [1] * size
# The find function here is the same as that in the disjoint set with path compression.
def find(self, x):
if x == self.root[x]:
return x
# Some ranks may become obsolete so they are not updated
self.root[x] = self.find(self.root[x])
return self.root[x]
# The union function with union by rank
def union(self, x, y):
rootX = self.find(x)
rootY = self.find(y)
if rootX != rootY:
if self.rank[rootX] > self.rank[rootY]:
self.root[rootY] = rootX
elif self.rank[rootX] < self.rank[rootY]:
self.root[rootX] = rootY
else:
self.root[rootY] = rootX
self.rank[rootX] += 1
def connected(self, x, y):
return self.find(x) == self.find(y)
# Test Case
uf = UnionFind(10)
# 1-2-5-6-7 3-8-9 4
uf.union(1, 2)
uf.union(2, 5)
uf.union(5, 6)
uf.union(6, 7)
uf.union(3, 8)
Terminologies
- Parent node: The direct parent of a node of a vertex
- Root node: A node without a parent node; it can be viewed as the parent node of itself
Base Implementation
To implement disjoint set there are 2 main functions that need to get covered:
- Find function finds the root node of a given vertex
- Union function unions two vertices and makes their root nodes the same
- isConnected function will just call find for 2 nodes and return if they're equal
From these 2 functions, there's actually 2 basic implementations based on what you need:
- Quick find will have find as , but the union function is
- Quick union will have an overall better runtime complexity for union, but find is worse
- They didn't actually mention runtimes here, idk
Quick Find
| Union Find Constructor | Find | Union | Complexity |
|---|---|---|---|
- Find:
self.rootjust acts as an lookup array for each node, so finding the root of any node at index if justself.root[i] - Union: To union 2 nodes and ,
x, yyou need to:- Check if they have the same parent, if so exit
- If not, then you need to pick one of the two nodes parents, in our implementation we choose
root[x], and update all of the other nodes parents to that- i.e. for each node in
self.rootthat is equal toroot[y], change it toroot[X]
- i.e. for each node in
So it's pretty simple - keep a single array self.root that has an mapping from each index to it's parent, and on Union update nodes by looping over the array and altering the mapping
# UnionFind class
class UnionFind:
def __init__(self, size):
self.root = [i for i in range(size)]
def find(self, x):
return self.root[x]
def union(self, x, y):
rootX = self.find(x)
rootY = self.find(y)
if rootX != rootY:
for i in range(len(self.root)):
if self.root[i] == rootY:
self.root[i] = rootX
def connected(self, x, y):
return self.find(x) == self.find(y)
# Test Case
uf = UnionFind(10)
# 1-2-5-6-7 3-8-9 4
uf.union(1, 2)
uf.union(2, 5)
uf.union(5, 6)
uf.union(6, 7)
uf.union(3, 8)
uf.union(8, 9)
print(uf.connected(1, 5)) # true
print(uf.connected(5, 7)) # true
print(uf.connected(4, 9)) # false
# 1-2-5-6-7 3-8-9-4
uf.union(9, 4)
print(uf.connected(4, 9)) # true
Quick Union
Quick union is generally more efficient overall than quick find:
- Find:
self.rootwill hold the immediate parent nodes for any node, but parent nodes themselves may be children so there has to be an actual traversal upself.rootduring find- This condition should end once we've reached
x = self.root[x]which refers to a root node
- This condition should end once we've reached
- is the number of vertices in the graph, and so in the worst case scenario the number of operations to reach the root vertex is which represents the height of the tree
- In a linked list (worst case)
- In a perfect binary tree
- Worst case if it's a perfectly linked list, and you start at the bottom and need to reach root
- Best case if each node is independent
- Space complexity still storing array
- Union: Simply choose one of the parents, and make it the others parent
- There's a stopping point if
rootX == rootY, but honestly this isn't necessary...just update on the fly and return would have the same results with an unnecessary index alteration
- There's a stopping point if
- Checking connectivity in this case is equal to the
findoperation time complexity
# UnionFind class
class UnionFind:
def __init__(self, size):
self.root = [i for i in range(size)]
def find(self, x):
while x != self.root[x]:
x = self.root[x]
return x
def union(self, x, y):
rootX = self.find(x)
rootY = self.find(y)
if rootX != rootY:
self.root[rootY] = rootX
def connected(self, x, y):
return self.find(x) == self.find(y)
# Test Case
uf = UnionFind(10)
# 1-2-5-6-7 3-8-9 4
uf.union(1, 2)
uf.union(2, 5)
uf.union(5, 6)
uf.union(6, 7)
uf.union(3, 8)
uf.union(8, 9)
print(uf.connected(1, 5)) # true
print(uf.connected(5, 7)) # true
print(uf.connected(4, 9)) # false
# 1-2-5-6-7 3-8-9-4
uf.union(9, 4)
print(uf.connected(4, 9)) # true
Optimizations
Both of the above implementations have 2 fatal flaws:
- Union in quick find will always take time
- If union in quick union accidentally forms a perfectly linked list, which can happen if we go from independent nodes and connect them sequentially to their neighbor, then find will be in as well
Both of these can be helped by 2 specific optimizations:
- Path compression helps to remove the recursive calls in
find - Union by rank is a self-balancing metric to avoid perfectly linked lists and ensure the height of the tree is at most
| Operation | Average Complexity |
|---|---|
| Union (Put) | |
| Find (Get) | |
| Delete | Not Applicable |
| Traverse / Search |
Union By Rank
To fix the linked list problem in quick union, we can utilize union by rank, which is a sort of self balancing graph concept so that we avoid creating perfectly linked lists:
-
Rank here refers to how we choose which parent to utilize during union operation
- In past implementations, we just randomly hard coded either
root[X]orroot[Y], but this can be done smarter - Rank refers to the height of each vertex, and so when we union 2 vertices, we choose the root with the larger rank
- In past implementations, we just randomly hard coded either
-
Merging the shorter tree under the taller tree will essentially cause the taller tree to widen. If we added the taller tree to the shorter tree, it would cause the shorter tree to lengthen, which is bad
-
Union will now utilize the
self.rankarray to continuously judge unions of components- Union needs to call
findhere to find the root node, so time complexity the same asfind
- Union needs to call
-
Find still traverses recursively, but what's changed is that cannot occur anymore since we are constantly unioning by largest rank
- Best case with each node as it's own parent it'll be find
- Medium / worst case, ideally worst case is close to a balanced tree,
- Actually, after googling this, in the worst-case scenario when we repeatedly union components of equal rank, the tree height will at most become , so the find operation in the worst scenario is
# UnionFind class
class UnionFind:
def __init__(self, size):
self.root = [i for i in range(size)]
self.rank = [1] * size
def find(self, x):
while x != self.root[x]:
x = self.root[x]
return x
def union(self, x, y):
rootX = self.find(x)
rootY = self.find(y)
if rootX != rootY:
# If rootX "deeper", set rootY to X
if self.rank[rootX] > self.rank[rootY]:
self.root[rootY] = rootX
# If rootY deeper, set rootX to it
elif self.rank[rootX] < self.rank[rootY]:
self.root[rootX] = rootY
# else pick one, and then we know it's rank has increases
# - above, the rank doesn't increase because the lesser rank appended
else:
self.root[rootY] = rootX
self.rank[rootX] += 1
def connected(self, x, y):
return self.find(x) == self.find(y)
# Test Case
uf = UnionFind(10)
# 1-2-5-6-7 3-8-9 4
uf.union(1, 2)
uf.union(2, 5)
uf.union(5, 6)
uf.union(6, 7)
uf.union(3, 8)
uf.union(8, 9)
print(uf.connected(1, 5)) # true
print(uf.connected(5, 7)) # true
print(uf.connected(4, 9)) # false
# 1-2-5-6-7 3-8-9-4
uf.union(9, 4)
print(uf.connected(4, 9)) # true
Path Compression
Path compression can ideally help with the recursive nature of the find function - in all previous iterations, we constantly had to traverse self.root parent nodes to find the root node
If we search for the same root node again, we repeat the same operations, is there any good way to cache this result or something? Yes! After finding the root node, simply bring it back and update all nodes in self.root to point at that root node instead of their parent nodes
- The only major change in the implementation below, is that we update
self.root[x] = self.find(self.root[x])if we don't seex = self.root[x]- i.e. we update
self.rooton the fly, and once we find the actual root node we can return it back down the stack to update each entry ofself.root
- i.e. we update
# UnionFind class
class UnionFind:
def __init__(self, size):
self.root = [i for i in range(size)]
def find(self, x):
if x == self.root[x]:
return x
self.root[x] = self.find(self.root[x])
return self.root[x]
def union(self, x, y):
rootX = self.find(x)
rootY = self.find(y)
if rootX != rootY:
self.root[rootY] = rootX
def connected(self, x, y):
return self.find(x) == self.find(y)
# Test Case
uf = UnionFind(10)
# 1-2-5-6-7 3-8-9 4
uf.union(1, 2)
uf.union(2, 5)
uf.union(5, 6)
uf.union(6, 7)
uf.union(3, 8)
uf.union(8, 9)
print(uf.connected(1, 5)) # true
print(uf.connected(5, 7)) # true
print(uf.connected(4, 9)) # false
# 1-2-5-6-7 3-8-9-4
uf.union(9, 4)
print(uf.connected(4, 9)) # true
Map Reduce Connected Componenets
Pregel is a way to do generic BFS and Graph Traversals in the MapReduce world, and there are ways to implement Connected Components via BFS using Pregel framework
you discuss Pregel in other areas, but it's useful to note here as some popular large scale data processing engines use this
Minimum Spanning Tree
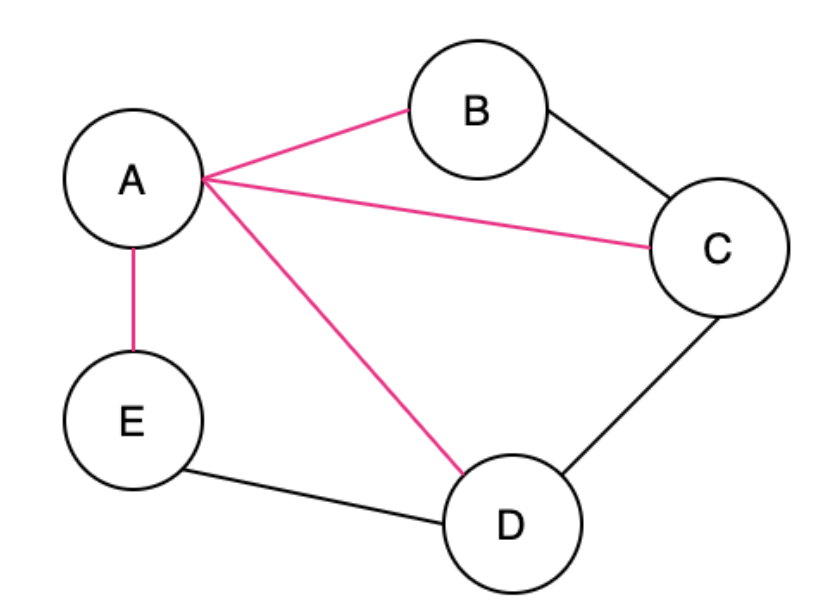
A Spanning Tree (ST) is a connected subgraph where all vertices are connected by the minimum number of edges
In my opinion it seems similar to a Span in a Vector Space which describes all of the orthonormal basis vectors that can be combined to create any vector in that space, but it's really not
The pink edges below show the ST
A Minimum Spanning Tree (MST) is when there are weights in a graph, you ideally can find the ST with the smallest total weight
An undirected graph can have multiple ST's and MST's
A cut in Graph Theory is a way to split up the Vertices and Edges in a Graph into 2 distinct sets, essentially cutting it to create 2 disjoint subsets
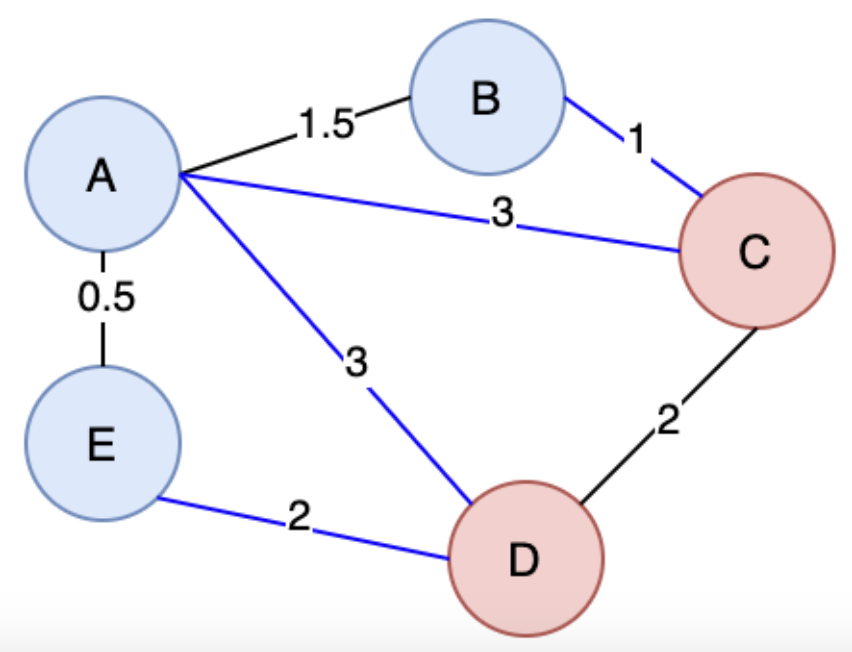
So the cut property, which will help us run different algorithms, says for any Cut of the Graph , if the weight of an Edge in a Cut-Set is strictly less than all other Edges in , then belongs to all MST's of
The proof above would rely on contradiction and goes something along the lines of "well if you didn't have that edge, in the MST, then you could add it and create a cycle that crosses the cut at least twice (first and newly added edge), and then if you removed the other Edge greater than it, it would result in a MST less than the original one"
MST algorithms are useful to find solutions to things like "min number of vertices to connect all points" similar to traveling salesman
Kruskal
Kruskal's Algorithm is for creating a Minimum Spanning Tree from a Weighted Undirected Graph. It uses sorting and UnionFind to solve for MST
- Kruskal's Algorithm will:
- Sort all edges, taking time using a typical sorting algorithm
- Starting smallest, for each edge:
- Check if the vertices of the edge are in the same connected component - which can be done via UnionFind and takes lookup and add time
- This essentially shows us if it would create a cycle / unnecessary edge
- Once you reach edges we've constructed our MST
- Check if the vertices of the edge are in the same connected component - which can be done via UnionFind and takes lookup and add time
| Time Complexity | Space Complexity |
|---|---|
Prim
Prim's Algorithm is another algorithm for creating a Minimum Spanning Tree from a Weighted Undirected Graph. It uses 2 sets to solve for MST
- Start with
MST = set()empty set, andNVisited = set(all_V)full of every vertex - Start with an arbitrary vertex
- For each step find all edges that connect
MST <--> NVisitedand take the minimum edge, and add that Vertex into MST- *Remember - The edge that connects two disjoint sub-graphs is a cut
- Time complexity is all around building min-heap, and then after that you are simply traversing unvisited nodes which is at most so the min-heap building will dominate time complexity
- Inserting into min-heap is , and you do that for all edges
- *Remember - The edge that connects two disjoint sub-graphs is a cut
- So at each step find the minimum edge crossing the cut, add the Vertexes to MST, and remove them from NVisited
- For each step find all edges that connect
Finding all the edges that connect the 2 sets is the majority of complexity here, and typically is solved using
| Time Complexity | Space Complexity |
|---|---|
Python Code
Pseudocode: is the set of visited Vertices, is the set of unvisited Vertices
T = ∅;
U = { 1 };
while (U ≠ V)
let (u, v) be the lowest cost edge such that u ∈ U and v ∈ V - U;
T = T ∪ {(u, v)}
U = U ∪ {v}
return(T)
Shortest Path
Breadth First Search can help us find the shortest path between 2 nodes in an unweighted graph, but it can't help when the graph is weighted because there are so many more options!
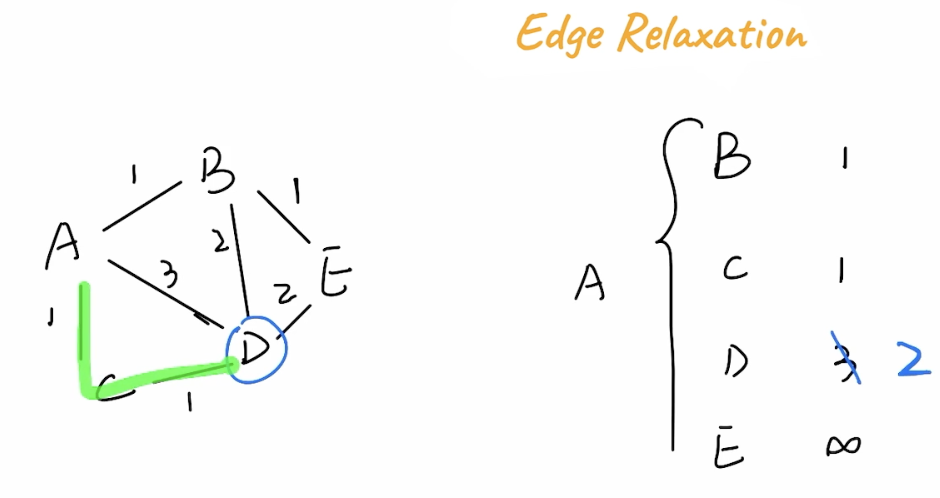
Edge Relaxation
The Edge Relaxation Property is the general property describing that although a path might take more hops, the weights on it might be smaller. In the below example A -> C -> D has a total weight of 2, while A -> D has a weight of 3
Djikstra
Djikstra's Algorithm can help solve the shortest path problem for graphs with non-negative weights
It solves the shortest path problem for a single Vertex, to all other Vertices
you also showcase this problem in Pregel Graph Processing Docs - in most cases you can't hold an entire graph in memory, and we'll have it written to disk somewhere, and Pregel is a Graph Traversal SDK for distributed datasets using Spark
Djikstra's algorithm is greedy, and essentially starts from a central point u and expands outwards, continually getting the min from the seen vertices to find shortest path to other vertices, it uses a min-heap to continuously select the vertex with the smallest known distance
you hold the state of our source vertex to each other vertex in the graph, and you hold "previous vertex" and length information in this table which will help us traverse recursively if you needed to rebuild the path. you can lookup distance from source to any other vertex in once it's complete, and then rebuilding path is at worst because it might be a linked list, and building this data structure and traversing the graph resutls in us visiting each vertex and each node so it would be around time complexity, but for each edge in a vertex you need to find the min vertex which is , therefore total time complexity is and space (since you need to store visited node info)
| Time Complexity | Space Complexity |
|---|---|
- Use cases:
- Network delay times from source to all sinks
- Traveling salesman that needs to cover all houses
- ...
Bellman-Ford
Bellman-Ford can help solve shortest path for all graph types including negative weights
Topological Sorting / Kahns Algorithm
Topological Sorting can help us traversing graphs when there are dependencies in directed acyclic graph's (DAGs), which is different from the above undirected weighted graphs
A key property is acyclic meaning there are no cycles in the graph! It wouldn't make sense if our prerequisites were required for our prerequisites!
- Use cases:
- Course scheduling with pre-requisites
- Workflow DAGs
- ...
The main algorithm for this is Kahn's Algorithm where you will basically iterate over all vertexes that have indegree = 0, and do something with them, and then decrement their downstream vertexes. This ultimately creates "levels" where multiple classes or jobs could be ran at the same time, and once they're all done you should be ready for our downstream vertexes (decrement indegree)
Since you are only iterating over edges and vertexes and doing increment / decrement, our space and time complexities are
| Time Complexity | Space Complexity |
|---|---|
You can also utilize straight up DFS for topological sort in some dependency graph problems by utilizing the 3-color masking method. Ultimately this relates to tracking state along the call stack, and if something is currently in the stack (lookup in state = defaultdict(int) dict) with state = 1, then it's a loop as you'll eventually form a cycle
Leaves Of A Binary Tree also has implementations for DFS, better DFS, and topological sort (BFS)
state[u] = 1
for v in deps[u]:
dfs(v)
state[u] = 2
order.append(u)
You need to do postorder traversal for this to work, as for any node you need to go completely explore all of the nodes it depends on - so you'll need some sort of dictionary like services_depends_on where each key is a specific node, and each item in the value list is another node that it will depend on. Once you go through all of those, and eventually add them to your order response, it'll be a topologically sorted array
Advanced Graph Topics
Below topics are more around Graph Theory, random stuff from lectures, etc
Graph Types
Graphs can have a few different topological setups as well - including:
- Multi-Relational: A graph that has more than one type of relationship between vertices
- In a social network we can have friend, family, coworker, etc..
- Formally, a multi-relational graph is defined as where is a set of edge-types
- The adjacency matrix in this scenario would be a matrix (a Tensor), where if there's an edge of type
typebetweenn1andn2- The tensor dimension here would be
- In a social network we can have friend, family, coworker, etc..
- Multiplex: A graph where there are multiple types of edges between the same pair of vertices, and furthermore each edge has it's own weight
- It introduces intra-layer (within) and inter-layer (between)
- Intra layer edges are edges that connect nodes for that layer type
- Inter layer edges are routes that connect nodes across different layer types
- Using transportation network as an example, where nodes are cities and the types are transportation types (flight, rail, train, car, walk, etc...)
- Intra layer edges represent getting between 2 citites using a single transportation type
- Inter layer routes represent getting between 2 cities utilizing more than 1 transportation type
- It introduces intra-layer (within) and inter-layer (between)
Sub Graph and Node Statistics
Graph statistics revolve around profiling graphs, sub-graphs, and other components by using various metrics and algorithms to understand their structure and properties - some are basic counting, some are combinatorics, and some are more advanced distributions. They answer questions about centrality, sparsity, density, connectivity, and other metrics
A common one to start off is cluster (sub-graph) density, and the intuition is finding the ratio of observed edges to possible edges within a cluster or sub-graph
The "hello world" of graph statistics is centrality utilizing the Florentine Families Dataset, which showcases relationships between families in Renaissance Florence, and typically should always have the Medici family as the most central node
To get to centrality and other metrics, there are some common statistics we'll define below:
- Degree: The number of edges connected to a vertex
- In-Degree: Number of incoming edges to a vertex (for directed graphs)
- Out-Degree: Number of outgoing edges from a vertex (for directed graphs)
- Degree Centrality: The number of edges connected to a vertex, normalized by the maximum possible degree
- If there are 8 nodes in a graph, and a specific node has 2 edges to 2 other nodes, it's degree centrality would be (\frac27)
- Path Length: The number of edges in the shortest path between two vertices
- Clustering Coefficient: A measure of the degree to which nodes in a graph tend to cluster together
- For a vertex, it's the ratio of the number of edges between its neighbors to the number of possible edges between those neighbors
- For the whole graph, it's the average clustering coefficient of all vertices
- Betweenness Centrality: A measure of how often a node appears on the shortest paths between other nodes
- Betweenness shows how often a node lies on the shortest path between two other nodes, and these nodes can be considered "route hubs" of sorts
- Cincinnati is a good example used to illustrate betweenness centrality in transportation networks, no one ever stops there, everyone just drives through it
- Eigenvector Centrality: A measure of a node's influence based on the influence of its neighbors
- Sum of centrality scores of neighbors
- Closeness Centrality: A measure of how close a node is to all other nodes in the graph, based on the average shortest path length from the node to all other nodes
- Inverse of average shortest path length to all other nodes
- Gives information on how close a node is to all other nodes, and simply showcases what node, even if it's not as important, is closest to everything
- Subgraph classifications and definitions:
- Closed Triangles: Sets of three nodes where each node is connected to the other two nodes
- Ego Graphs*: Subgraphs consisting of a focal node, and all the nodes that are connected to that focal node
- Most likely is star shaped
- Motifs: Patterns of node connectivity that occur more than would be expected by chance
- Basically a catch all for sub-graph patterns - closed triangles and ego graphs are specific motifs
- Clustering Coefficient: Measures the proportion of closed triangles in a node's local neighborhood
- Can be used to find communities in a network, which help to show how clustered a node is
- \frac{\text{# of triangles in a node's local neighborhood}}{\text{# of possible triangles in a node's local neighborhood}}
Eigenvectors in Graphs
Seeing an Eigenvector scared me - they're actually utilized in Graph Theory to understand how certain graphs change as operations are performed on them
Eigenvectors can be used to find equilibrium points of graphs, which ultimately are points that aren't affected by any changes that are made to it
Graphs are just matrices, so eigenvectors help us understand their properties and behaviors - an adjacency matrix represents the connections between nodes, and therefore eigenvectors represent directions in which the graph can be transformed without changing its structure
An adjacency matrix can be seen as a transformation that acts on "node vectors", or functions defined on the graphs nodes
The intuition of an eigenvector on an adjacency matrix is that it allows us to find important nodes in a graph, where the eigenvector centrality of a node is proportional to the sum of the centralities of its neighbors
Some definitions on GeeksForGeeks
If we wanted to find a function below that essentially brings a node to the real numbers, we can use a vector with one entry for any node - i.e. a node vector
Backtracking a bit, this ends up relating to harmonic functions, which are function that is always equal to it's average on circles - this means the function is always reverting towards it's average within some bounding box
The analogy of eigenvectors on graphs is a node vector so that each entry is always equal to the average of the entries of it's neighbors - i.e. within a small bounding box (neighbors), we want the eigenvector entries to always be equal to the average of it's neigbors. Therefore, if an eigenvector's value is large, we can see that it's node (the average of it's neighbors) means that node and it's neighbors must be a sort of critical central component
This node vector intuitively encodes some information about adjacency between nodes, and ultimately this encoded vector would have to be constant over each connected component of a graph (they're all neighbors)
Therefore, at the end, eigenvector centrality (eigencentrality) is a measure of the influence of a node in a network!
PageRank and Katz centrality are related concepts that build upon eigenvector centrality to rank nodes in a network, and they are natural variants of this eigencentrality
The component of the related eigenvector gives the relative centrality score of the vertex !
What can this help us with graph profiling:
- Graph structure: Eigenvectors can reveal overall "sub-clusters" within a graph, and reveal if the entire graph is highly connected
- Centrality measures: The eigenvector values are measure's of node importance that consider both the node's direct connections, and their neighboring node's
- Assigning higher scores to nodes that are connected to other highly connected central nodes
- Network dynamics: Eigenvectors can be used to understand the stability or equilibrium of processes on the network, and can even help us find steady state distributions and feeback loops (similar to markov chains)
- Community detection: Eigenvectors can be used in community detection algorithms to identify groups of nodes that have similar connectivity patternss
Proof / Math
- For a given graph with vertices
- is the adjacency matrix such that
- if vertex is linked to vertex
- 0 otherwise
- is a set of neighbors of vertex
Then, the relative centrality score of a vertex can be defined as:
Rearranging the above equation (somehow) you can get to vector notation where:
There'll be many eigenvalues for which a non-zero eigenvector solution exists, but extra conditions such as all entries in the eigenvector be non-negative (Perron-Frobenius) implies that only the greatest eigenvalue is considered for eigenvector centrality
The component of the related eigenvector gives the relative centrality score of the vertex !
Graph Statistics
Now they Sub-Graph and Node Statistics are covered above, there's a natural way to extend those to entire graphs
The typical proposal is to extract these metrics utilizing Graph Kernel Methods which are classes of ML algorithms that can be used to learn from data that's represented as a graph
Most graph kernel methods are proper ML algorithms, and so we'll define them further in Graph Neural Networks